
ABSTRAK
Dalam artikel ini, kami mengusulkan sistem AR yang memfasilitasi interaksi alami pengguna dengan objek virtual dalam lingkungan augmented reality. Sistem ini terdiri dari tiga modul: estimasi pose dan bentuk manusia, kalibrasi ruang kamera, dan simulasi fisika. Modul pertama memperkirakan pose dan bentuk 3D pengguna dari aliran video RGB tunggal, sehingga mengurangi biaya pengaturan sistem dan memperluas aplikasi potensial. Modul kalibrasi ruang kamera memperkirakan posisi ruang kamera pengguna untuk menyelaraskan pengguna dengan gambar RGB input. Simulasi fisika memungkinkan interaksi yang mulus dan alami secara fisik dengan objek virtual. Dua aplikasi prototipe yang dibangun di atas sistem membuktikan peningkatan kualitas interaksi, yang mendorong pengalaman pengguna yang lebih mendalam dan intuitif.
1 Pendahuluan
Untuk berbagai aplikasi augmented reality (AR), seperti uji coba virtual dan pelatihan virtual, penting untuk menyediakan interaksi alami yang lancar antara manusia nyata dan objek virtual. Untuk memungkinkan interaksi tersebut biasanya diperlukan perekaman gerakan manusia secara langsung. Dalam permainan bola voli AR, misalnya, tindakan seperti memukul atau memblokir bola virtual harus dicerminkan secara meyakinkan dalam konteks AR.
Untuk menangkap sendi-sendi seluruh tubuh manusia, berbagai sensor gerak dan pakaian penangkap gerak telah digunakan [ 1 – 4 ]. Namun, sifat intrusif dari sistem berbasis penanda dan beban pakaian penangkap gerak menimbulkan hambatan yang signifikan terhadap adopsi yang meluas dalam penggunaan AR sehari-hari. Pendekatan alternatif melibatkan penggunaan sensor RGB-D untuk menghitung pose 3D dan memperkirakan bentuk 3D berdasarkan informasi warna dan kedalaman [ 5 – 8 ]. Baru-baru ini, pendekatan berbasis pembelajaran mendalam lebih jauh di bidang ini dengan memperkirakan informasi pose 3D hanya menggunakan sensor RGB [ 9 – 11 ], yang mengarah pada pengembangan berbagai skenario interaksi virtual [ 12 – 14 ]. Pendekatan berbasis pembelajaran mendalam telah diperluas untuk menyediakan informasi bentuk 3D, yang sangat penting untuk menangani tabrakan dan oklusi di lingkungan AR [ 15 – 18 ].
Dalam artikel ini, kami mengusulkan sistem AR yang menggunakan video RGB sebagai input, memperkirakan pose dan bentuk 3D pengguna, dan memfasilitasi interaksi pengguna dengan objek virtual 3D. Seperti yang ditunjukkan pada Gambar 1 , sistem ini terdiri dari tiga modul untuk (1) estimasi pose dan bentuk manusia, (2) kalibrasi ruang kamera, dan (3) simulasi fisika.
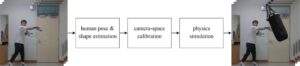
Pose dan bentuk manusia (HPS) yang diperkirakan oleh modul pertama direpresentasikan dalam model manusia parametrik, SMPL-X [ 18 ]. Karena model SMPL-X adalah entitas geometris, penanganan interaksinya dengan objek virtual mungkin tampak mudah. Sayangnya, model yang diperkirakan tidak didefinisikan dalam dunia atau ruang kamera. Untuk memungkinkan model manusia bergerak dan berinteraksi dengan objek virtual yang dinamis di lingkungan AR, kita perlu mengkalibrasi model manusia setiap bingkai sehingga ditransformasikan dengan benar ke dalam dunia atau ruang kamera. Fokus artikel ini adalah pada kalibrasi ruang kamera . Akhirnya, modul ketiga untuk simulasi fisika diimplementasikan menggunakan mesin permainan. Kontribusi kami dirangkum sebagai berikut:
- Kami menyajikan solusi AR yang memungkinkan interaksi manusia nyata dengan objek virtual 3D. Dengan hanya menggunakan satu umpan video RGB sebagai input, solusi ini mendukung interaksi alami berbasis bentuk 3D.
- Dibangun di atas teknik pembelajaran mendalam yang seimbang antara akurasi dan efisiensi, solusinya merekonstruksi dan mengkalibrasi model manusia dengan cara yang kuat.
- Solusinya bekerja dalam lingkungan AR yang mudah diatur, dan karena itu dapat digunakan di berbagai aplikasi AR.
2 Pekerjaan Terkait
2.1 Estimasi Pose dan Bentuk Manusia
Tantangan signifikan dalam interaksi seluruh tubuh terletak pada pelacakan gerakan manusia yang akurat. Metode tradisional dalam VR, AR, dan grafik sering kali mengandalkan pakaian dan sensor penangkap gerak [ 19 , 20 ], sementara yang lain mengeksplorasi pengaturan berbasis penanda [ 1 , 3 ]. Di luar pakaian seluruh tubuh, sistem alternatif menggunakan penanda jarang atau sensor yang dapat dikenakan yang dikombinasikan dengan kinematika terbalik atau SLAM. Roth dkk. [ 21 ] menunjukkan bahwa set penanda benda kaku yang dikurangi dengan kinematika terbalik menurunkan latensi dan beban tugas dalam VR tanpa mengorbankan kepemilikan tubuh. Yi dkk. [ 4 ] mengusulkan EgoLocate, yang mengintegrasikan mocap inersia dan SLAM monokuler untuk mencapai penangkapan dan pelokalan gerakan manusia secara real-time menggunakan enam IMU dan kamera monokuler. Ghorbani dkk. [ 22 ] menerapkan model pembelajaran mendalam untuk memperkirakan gerakan dan bentuk manusia dari masukan mentah sistem penangkapan gerak berbasis penanda. [ 2 ] menggunakan model Bi-LSTM untuk merekonstruksi gerakan manusia hanya dari empat penanda. Kim et al. [ 23 ] mengusulkan DAMO, pemecah mendalam yang digeneralisasi di seluruh konfigurasi penanda melalui pengoptimalan ujung ke ujung. Meskipun ada kemajuan ini, sistem berbasis penanda dan sensor masih mengalami keterbatasan mobilitas [ 24 ] dan biaya pengaturan yang tinggi karena perangkat keras dan kalibrasi khusus.
Menghadapi keterbatasan metode berbasis penanda dan sensor, para peneliti telah memanfaatkan sensor RGB-D, seperti Kinect [ 25 ], untuk estimasi gerakan seluruh tubuh [ 5 , 7 , 8 , 26 ]. Shum et al. [ 8 ] merancang kerangka kerja untuk pelacakan gerakan waktu nyata menggunakan Kinect. Cui et al. [ 5 ] menggunakan dua sensor Kinect, yang diposisikan di depan dan belakang, untuk menangkap gerakan manusia secara komprehensif. Kim et al. [ 26 ] menggabungkan sensor RGB dan ToF berkecepatan tinggi untuk menangkap pose manusia yang dinamis. Ren et al. [ 7 ] menggunakan jaringan saraf konvolusional (CNN) bersama dengan sensor kedalaman untuk menangkap gerakan manusia dalam skenario skala besar.
Solusi pembelajaran mendalam berbasis RGB [ 9 – 11 ] telah muncul sebagai alternatif efektif untuk estimasi pose 3D tanpa perangkat keras khusus. Metode yang ada untuk estimasi pose 3D menggunakan kamera RGB monokuler terbagi dalam dua kategori: tahap tunggal vs. dua tahap. Teknik tahap tunggal [ 27 , 28 ] secara langsung melokalisasi titik kunci tubuh 3D dari gambar input. Sun et al. [ 28 ] menggunakan operasi soft-argmax untuk mendapatkan lokasi sendi dari peta panas 3D, sedangkan Moon et al. [ 27 ] mengusulkan pendekatan atas-bawah untuk estimasi pose multiperson. Selain itu, Apple memperkenalkan ARKit [ 29 ], sebuah kerangka kerja yang memperkirakan pose manusia 3D dari gambar RGB untuk aplikasi AR. Sebaliknya, metode dua tahap [ 30 – 33 ] memanfaatkan estimasi pose 2D yang akurat, mengangkat titik kunci ke ruang 3D. Pavllo et al. [ 32 ] memperkenalkan konvolusi temporal yang melebar, dan Zheng et al. [ 33 ] menggunakan Vision Transformer untuk menangkap ketergantungan spasial dan temporal.
Model linear multiperson berkulit (SMPL) [ 34 ] telah mengkatalisasi serangkaian studi yang bertujuan untuk memperkirakan HPS 3D menggunakan model pembelajaran mendalam. Dengan merepresentasikan tubuh manusia 3D sebagai fungsi parameter HPS yang dapat dibedakan, model ini sangat cocok untuk pelatihan jaringan saraf ujung ke ujung. Kontribusi penting dalam domain ini termasuk SMPLify [ 15 ], Human Mesh Recovery (HMR) [ 16 ], SMPLify-X [ 18 ], dan VIBE [ 17 ]. Metode estimasi HPS dapat dilakukan melalui teknik optimasi atau regresi. Metode berbasis optimasi [ 15 , 35 – 37 ] menyelaraskan model tubuh dengan isyarat gambar seperti sendi, korespondensi verteks padat atau topeng segmentasi 2D. Dalam konteks optimasi, misalnya, Luvizon et al. [ 38 ] memperluas estimasi HPS 3D ke pengaturan multi-manusia yang sadar pemandangan dari satu video RGB. Di sisi lain, metode berbasis regresi [ 16 , 17 , 39 – 42 ] melatih jaringan menggunakan kerugian yang mirip dengan fungsi tujuan optimasi, sehingga memungkinkannya untuk memprediksi parameter model tubuh.
2.2 Interaksi Seluruh Tubuh
Di masa lalu, untuk mempelajari interaksi seluruh tubuh dalam lingkungan virtual, sistem penangkapan gerak berbasis penanda umum digunakan [ 43 – 46 ]. Debarba et al. [ 44 ] meningkatkan interaksi dengan objek virtual dengan memanfaatkan pengaturan yang melibatkan 4 penanda LED dan 14 kamera untuk menangkap gerakan manusia. Young et al. [ 46 ] menerapkan tos di lingkungan virtual dengan menggunakan sistem penangkapan gerak.
Munculnya sensor RGB-D telah memacu penelitian ekstensif ke dalam aplikasi interaksi seluruh tubuh. Seperti yang ditekankan oleh Caserman et al. [ 47 ], aplikasi VR yang menggunakan data gerakan seluruh tubuh dari kamera RGB-D mencakup spektrum aktivitas yang luas. Ini termasuk memanjat tangga virtual [ 48 ], exergames berbasis bersepeda [ 49 – 51 ], tugas manufaktur kolaboratif yang melibatkan interaksi manusia-robot [ 52 ], dan pembuatan permainan peran [ 53 ].
Selain aplikasi VR, produk komersial seperti Kinect dan RealSense telah memungkinkan interaksi seluruh tubuh dalam AR. Meskipun solusi komersial ini tersedia, eksplorasi ilmiah mengenai interaksi seluruh tubuh dalam AR masih relatif sedikit [ 54 ]. Selain itu, meskipun sistem ini memberikan fleksibilitas lebih dibandingkan dengan sistem berbasis penanda, sistem ini sering kali memerlukan penggunaan beberapa sensor RGB-D, yang menyebabkan pengaturan yang rumit dan biaya yang lebih tinggi.
Kemajuan terbaru dalam pembelajaran mendalam telah memungkinkan sejumlah pendekatan untuk mengatasi tantangan interaksi manusia-virtual. Hwang et al. [ 55 ] mengusulkan model estimasi pose manusia 3D ringan yang diterapkan pada rekonstruksi avatar virtual, dengan potensi perluasan pada interaksi manusia-virtual. Nguyen et al. [ 13 ] mengembangkan aplikasi kebugaran AR yang mendukung interaksi seluruh tubuh dengan mengintegrasikan estimasi pose 3D ke dalam antarmuka latihan. Wu et al. [ 14 ] menciptakan sistem pelatihan seni bela diri berbasis AR yang memungkinkan interaksi seluruh tubuh secara real-time melalui evaluasi gerakan yang dipandu pose. Studi terbaru [ 56 – 58 ] telah memperluas interaksi berbasis avatar ke dalam lingkungan yang imersif.
Selain metode berbasis kerangka, bentuk tubuh manusia telah menarik perhatian signifikan untuk interaksi seluruh tubuh, khususnya pendekatan berbasis SMPL [ 34 ]. De et al. [ 59 ] menggunakan HMR untuk memperkirakan HPS dan membuat agen virtual untuk VR interaktif. Selain itu, Šarić et al. [ 60 ] memperkenalkan sistem kolaborasi telemedicine berbasis realitas yang diperluas yang menyajikan avatar 3D pasien ke dokter jarak jauh, memanfaatkan estimasi HPS 3D yang diperoleh dari model pembelajaran mendalam. Studi terbaru telah memperluas interaksi seluruh tubuh ke dalam lingkungan yang imersif [ 61 ] dan lingkungan AR [ 62 , 63 ].
Terinspirasi oleh metode berbasis pembelajaran, artikel ini mengusulkan jaringan estimasi HPS, yang memanfaatkan informasi bentuk untuk berinteraksi dengan objek virtual dalam lingkungan AR. Sistem kami mudah disiapkan, tidak memerlukan perangkat tambahan, dan terbukti hemat biaya.
3 Kalibrasi Ruang Kamera
Pengaturan AR kami ditunjukkan pada Gambar 2 : Seorang pengguna bergerak di lantai dan layar besar di depan pengguna menampilkan tampilan cermin lingkungan menggunakan webcam RGB, yang dipasang di atas layar dan menangkap seluruh tubuh pengguna. Lingkungan yang ditangkap dilengkapi dengan objek virtual sehingga pengguna dapat berinteraksi dengan objek tersebut.


Dalam pengaturan AR kami, model manusia tidak terlihat oleh pengguna, tetapi mesh-nya digunakan, misalnya, untuk mendeteksi tabrakan dengan objek virtual. Dalam implementasi saat ini, modul simulasi fisika diimplementasikan menggunakan mesin Unity. Namun, modul ini dapat dengan mudah digantikan oleh mesin komersial atau open-source lainnya.
3.1 Jaringan Kalibrasi
HMR menggunakan model kamera perspektif lemah , yang diimplementasikan sebagai proyeksi ortografis plus penskalaan . Akibatnya, model manusia yang direkonstruksi tidak ditempatkan dengan benar dalam sistem koordinat 3D kamera nyata, misalnya, kedalaman ruang kameranya mungkin terlalu tinggi atau terlalu rendah. Kemudian, kita tidak hanya akan kehilangan tabrakan antara model manusia dan objek virtual tetapi juga kita akan menangani oklusi di antara keduanya secara tidak tepat. Oleh karena itu, model manusia harus dikalibrasi sehingga diubah menjadi ruang kamera perspektif penuh .
Gambar 3 mengilustrasikan proses kalibrasi. Langkah penting untuk kalibrasi adalah memperkirakan koordinat ruang-kamera dari sambungan akar . Setelah diperkirakan dengan benar, semua koordinat sambungan lainnya dapat segera ditentukan menggunakan posisi mereka relatif terhadap akar, yang disimpan dalam pose 3D.
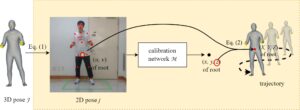

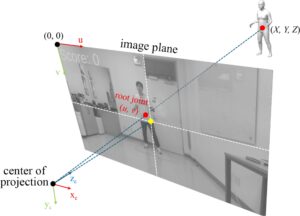
3.2 Pembahasan
Secara umum, metode HPS yang didasarkan pada model perspektif lemah tidak akurat dalam memprediksi pose 3D, karena proyeksinya yang mendekati ortografis. Misalnya, tingkat distorsi perspektif yang tinggi dalam swafoto sering kali menyebabkan pose 3D yang tidak dapat diterima. Sebaliknya, pose yang diprediksi akan dapat diterima jika pengguna cukup jauh dari kamera. Hal ini terjadi pada pengaturan AR kami yang ditunjukkan pada Gambar 2 , di mana jarak yang cukup jauh antara kamera dan pengguna harus dipertahankan untuk menangkap gerakan seluruh tubuh pengguna.
Baru-baru ini, masalah model perspektif lemah telah ditangani secara langsung oleh beberapa upaya yang memperkirakan parameter intrinsik kamera [ 65 , 66 ] atau kedalaman pengguna [ 67 ]. Sementara metode ini meningkatkan akurasi 3D, metode ini memperkenalkan kompleksitas pemrosesan dan pelatihan tambahan. Strategi kami untuk mengadopsi HMR dan mengintegrasikannya dengan jaringan kalibrasi dapat dianggap seimbang antara akurasi dan efisiensi. (Kami melatih HMR dengan dataset BEDLAM [ 68 ], yang menyediakan data sintetis yang beragam dan realistis).

Jaringan asli yang diusulkan oleh Pavllo et al. [ 32 ] didasarkan pada konvolusi temporal yang melebar, yang memprediksi lintasan menggunakan data masa lalu dan masa depan. Di sisi lain, mereka mengusulkan konvolusi kausal untuk aplikasi waktu nyata, yang hanya memiliki akses ke frame masa lalu dan memprediksi lintasan frame saat ini. Pembaca dirujuk ke Lampiran C untuk visualisasi kedua jenis konvolusi tersebut..

Kami mengevaluasi tiga model estimasi lintasan dengan Subjek 9 dan 11 dari dataset Human3.6M. Jelas, jaringan kalibrasi kami memerlukan lebih sedikit parameter dan FLOP daripada yang lain, seperti yang ditunjukkan pada Tabel 1 , membuatnya lebih cocok untuk aplikasi waktu nyata. Sangat menarik untuk menemukan bahwa sehubungan dengan kesalahan lintasan , yang didefinisikan sebagai perbedaan rata-rata dari posisi ground-truth dan prediksi root joint, jaringan kami adalah yang paling akurat, dan model dengan 27 frame lebih akurat daripada yang dengan 81 frame, yaitu, urutan input yang lebih panjang mengarah ke kesalahan yang lebih besar. Dengan temuan ini, kami berspekulasi bahwa dalam konvolusi kausal, frame saat ini memegang informasi paling penting untuk memprediksi posisi root joint, dan informasi yang kurang relevan dari frame sebelumnya terakumulasi selama urutan frame untuk menghambat prediksi yang tepat.
| # Bingkai masukan | Parameter | Gagal | Kesalahan lintasan |
|---|---|---|---|
| 1 bingkai | 4,24 juta | 8,46 juta | 147,0 mm2 |
| 27 bingkai | 8,51 juta | 16,99 juta | 147,7 mm |
| 81 bingkai | 12,70 juta | 25,38 juta | 181,3 mm |
4 Aplikasi
Peralatan AR yang kami tampilkan pada Gambar 2 terdiri dari webcam, PC, dan layar besar yang dapat diganti dengan TV. Peralatan ini mudah ditemukan di lingkungan sehari-hari, sehingga menyediakan platform permainan yang mudah disiapkan. Peralatan ini juga dapat digunakan untuk banyak aplikasi AR lainnya seperti uji coba virtual.
4.1 Aplikasi 1: Game Tinju
Estimasi bentuk manusia membuka pintu ke berbagai macam aplikasi AR. Kami telah mengembangkan prototipe permainan tinju, di mana pengguna meninju objek virtual. Pada Gambar 5 , pengguna bergerak di sekitar karung tinju dan terus meninjunya. Untuk secara meyakinkan menggabungkan objek virtual ke dalam lingkungan dunia nyata, kami menggunakan bentuk pengguna yang diestimasikan. Gambar 5 dengan jelas menunjukkan bahwa sistem kami mampu menangani oklusi antara objek nyata dan virtual. Untuk meningkatkan realisme, bayangan karung tinju virtual dibuat dan digabungkan ke dalam pemandangan menggunakan lantai virtual. Lantai virtual juga dapat digunakan, misalnya, untuk membuat bola virtual memantul di pemandangan nyata.

4.2 Aplikasi 2: Coba Virtual
Pengaturan AR kami yang disajikan dalam Gambar 2 dapat digunakan untuk banyak aplikasi AR lainnya seperti coba-coba virtual. Gambar 6 menunjukkan serangkaian snapshot yang memvisualisasikan interaksi real-time yang kompleks antara pakaian virtual dan model manusia yang direkonstruksi dengan metode yang disajikan dalam artikel ini. Dalam implementasi proof-of-concept ini, pakaian tersebut terdiri dari 8K vertex. Ini disimulasikan dengan XPBD (extended position-based dynamics) [ 73 ] yang diimplementasikan dalam Taichi [ 74 ], bahasa tingkat tinggi untuk pemrograman GPU, dan kueri proximity untuk segitiga yang bertabrakan dipercepat melalui hashing spasial [ 75 ].

4.3 Evaluasi dan Pembahasan
Tabel 2 menunjukkan waktu yang dikonsumsi oleh modul pertama untuk estimasi HPS (yaitu, oleh Yolo v8n + HMR) dan yang kedua untuk kalibrasi kamera (yaitu, oleh jaringan kalibrasi). Total waktu adalah 5,5 ms. Ketika digunakan untuk permainan tinju, waktu meningkat menjadi 6,6 ms, seperti yang ditunjukkan pada Tabel 3. Ini menyiratkan bahwa Unity menghabiskan 1,1 ms untuk simulasi dan rendering benda kaku. Sebaliknya, waktu meningkat menjadi 36,2 ms untuk aplikasi uji coba virtual, yang menyiratkan bahwa implementasi XPBD kami menghabiskan sekitar 30 ms.
| Model | Waktu (ms) |
|---|---|
| Yolo v8n | 3.04 |
| HMR | 2.22 |
| Jaringan kalibrasi | 0.24 |
| Total | 5.5 |
| Aplikasi | Waktu (ms) | FPS |
|---|---|---|
| Permainan tinju | 6.6 | 151 |
| Coba secara virtual | 36.2 | 27 |
Dengan menggunakan model kain yang sederhana, Gambar 6 menunjukkan implementasi bukti konsep. Pakaian yang lebih realistis dapat disimulasikan dengan XPBD, tetapi desain pakaian yang realistis menghadirkan tantangan tersendiri yang harus dikelola dengan cermat dalam sistem praktis. Misalnya, pakaian tersebut harus dirancang secara manual sehingga pakaian tidak saling menembus dengan jaring manusia saat inisialisasi (yaitu, pada pose T). Kami yakin bahwa upaya tersebut tidak terkait dengan kontribusi artikel ini saat ini. Kami membayangkan bahwa masalah tersebut dapat ditangani dalam karya mendatang yang ditujukan pada aplikasi pakaian yang serius.
Perangkat AR kami memiliki kekurangan tersendiri. Tidak seperti headset AR seperti HoloLens [ 76 ], Meta Quest 3 [ 77 ] dan Apple Vision Pro [ 78 ], layar besar tidak dapat memberikan persepsi kedalaman binokular, sehingga sering kali gagal menciptakan pengalaman yang mendalam bagi pengguna. Meskipun ada kekurangan berupa kurangnya persepsi kedalaman dan pencelupan, kami yakin bahwa aplikasi yang dapat dibangun pada perangkat AR kami berbeda dari yang ada pada headset AR, dan uji coba virtual adalah contoh yang baik untuk kategori aplikasi pertama.
5. Kesimpulan dan Pekerjaan Masa Depan
Artikel ini menyajikan solusi praktis yang memungkinkan interaksi alami manusia dengan objek virtual 3D dalam lingkungan AR hanya menggunakan kamera video RGB konvensional. Dibangun berdasarkan teknik pembelajaran mendalam yang memiliki keseimbangan yang baik antara akurasi dan efisiensi, solusi tersebut merekonstruksi dan mengkalibrasi model manusia dengan cara yang kuat sehingga dapat menangani tabrakan dan oklusi dengan sukses.
Meskipun pendekatan kami dapat memfasilitasi interaksi seluruh tubuh secara signifikan dalam AR, masih ada potensi untuk penyempurnaan lebih lanjut. Sistem AR kami bergantung pada teknik estimasi HPS, tetapi tidak menawarkan pelokalan 3D yang tepat karena keterbatasan model SMPL. Solusi kami mengatasi keterbatasan ini melalui model lintasan. Akan tetapi, model lintasan terbatas dalam kasus yang relevan dengan set data pelatihan. Ini dapat gagal dengan pose yang menantang, misalnya, saat pengguna berbaring. Ini akan membatasi potensi penerapan metode saat ini pada konten permainan dan hiburan. Untuk memperluas jangkauan penerapan, teknik tingkat lanjut perlu dikembangkan, sehingga meningkatkan kualitas interaksi.